1. 93216部队, 2.北京信息技术研究所 , 3. 93110部队
摘 要:针对战场环境数据量大、数据种类多的特点本文提出了基于VSM和AMMK-means的聚类信息推荐方法,为不同席位提供主动服务,增强指挥员的战场感知能力。本文首先使用VSM来表示战场信息的文本特征,然后采用AMMK-means聚类算法对战场信息进行分类,构建用席位兴趣模型,最后计算席位兴趣模型和候选信息之间的相似度并向席位推荐其感兴趣的战场信息。
关键词: 个性化推荐;信息特征向量;态势推荐;文本聚类
中图分类号:TP311.134.3
1 相关工作
基于内容的推荐算法是信息检索领域的重要研究内容[1]。其主要研究思路是:先获取信息的特征属性;再分析用户已经浏览过的信息生成用户画像并计算其与候选信息的特征相似度,最后根据相似度将相似度高的信息推荐给用户。因此,基于内容的推荐方法一般包含物品画像、用户画像和推荐生成三个步骤[2]。
物品画像就是将物品用特征信息来表示。描述物品的属性有结构化数据和非结构化数据。非结构化数据需要转化成为结构化数据才能在模型中使用。
2 基于VSM和AMMK-means的聚类
信息推荐方法
2.1 席位兴趣模型的构建
目前主流的文本特征表示模型主要包括四种:布尔模型、概率检索模型、语言模型和向量空间模型。
布尔模型使用 0和1 来表示向量元素的值,从本质上可以转变成向量空间模型,其优点是模型简单,缺点是文档信息损失较大。文本检索方面常用的概率检索模型基于词间相关性与概率排序来判断相关性。语言模型与概率检索模型类似其本质是基于概率和统计的模型。向量空间模型是信息检索领域经典的计算模型。在模型中,每个文档用一个特征向量来表示该文档中的多维信息。考虑到战场信息的高维性以及为了便于聚类战场信息从而构建席位用户兴趣模型,本文采用向量空间模型来表示战场信息特征向量。给定战场信息集合
VSM构建过程中首先要确定关键词集的维度m。关键词用于表征文档的特性,当关键词数量增加时随着m的增大,时间复杂度增大。在保证表征效果的前提下,为了减少时间开销本文提取每篇战场信息中的前5个关键词来表征该篇战场信息(一般取3和5效果最好),接着采用TF-IDF算法得出战场信息集合中关键词集的维度m。采用TF-IDF算法计算权重。TF-IDF算法的计算可以分成词频(TF)和逆文档频率(IDF)两部分,这两部分的乘积共同决定文档词语的权重。本文采用:
 2.2 基于AMM k-means 的算法的信息分类
2.2 基于AMM k-means 的算法的信息分类
目前数据挖掘领域聚类算法主要有基于模型的算法、基于网格的算法、基于密度的算法、基于距离的算法四种。其中基于模型的算法需要核心模型参数,才能保持数据拓扑性质,但其对初始参数较为敏感。基于网格的算法只与网格数有关不受聚类对象数限制,虽然聚类速度快但不适合高维数据。基于密度的算法主要代表是 DBSCAN 算法,虽然该算法抗噪能力强,但过分依赖阈值参数并且该算法在处理高维数据时存在困难。基于距离的聚类算法主要用在向量空间模型表示的文本上。这类算法代表为 K-means聚类算法,其优点为收敛速度快、容易处理高维数据。
同时使用K-means算法进行聚类也具有局限性。第一,该算法在聚类时要预先设定聚类数目。但在实际应用时很难给出精确的聚类数。对于不同的数据集,聚类数目的参考也没有选择依据,需要依靠大量训练实验。第二、该算法的初始聚类中心由随机方式获得。如果初始中心位置选择不合适很可能增加运算量并且得不到全局最优解。
最大最小距离聚类算法最早用于模式识别领域,通过试探聚类之间的欧几里得距离,将相距尽可能远的样本点作为初始中心进行聚类,能够有效地避免由于初始中心选择过近,导致聚类结果不佳的情况出现。并且在完成初始的聚类中心的选取之后,自然而然也有了希望生成的聚类的数目,弥补了K-均值聚类时未知类数目的不足。
4 实验分析
本章实验使用Data Castle 提供的财经新闻网站财新网10000 名用户的116225新闻浏览记录作为实验对象。实验采用 python 的第三方库jieba 分词器进行分词,根据实际新闻内容采用改进的哈尔滨工业大学信息检索中心的停用词表去除停用词。为了便于实验比较,本文所提方法VSM+AMMK-means与基于用户的协同过滤算法(User-Based CF)、基于物品的协同过滤算法(Item-Based CF)、基于VSM+Kmeans聚类推荐算法进行实验对比。每种方法都重复试验 5 次取平均值作为实验结果。

在实验中推荐结果N考虑了10、15、20、25和30。如表1所示在User-Based CF和Item-Based CF中,当K分别取10和15时效果最好。当聚类算法选取M=20时两种算法效果都优于其他聚类数。
本章方法要比 User-Based CF 和 Item-Based CF 两种协同过滤算法平均优于 8%,比 VSM+K-means 算法平均优于 2.3%;在召回率上,本章方法要比 User-Based CF 和 Item-Based CF 两种协同过滤算法平均优于 9%,比 VSM+K-means 算法平均优于1,3%。当推荐结果个数在 15~25 之间时,本章方法要比 User-Based CF 和 Item-Based CF 两种协同过滤算法平均优于 8.8%,比 VSM+K-means 算法平均优于 3.2%。从准确率P、召回率R和 F 值这三种评估指标分析,可见本章所提方法要优于参与比较的同类算法。
6 结论
针对战场环境数据量大、数据种类多的特点本文提出了基于VSM和AMMK-means的聚类信息推荐方法,为不同席位提供主动服务,增强指挥员的战场感知能力。本文首先使用VSM来表示战场信息的文本特征,然后采用AMMK-means聚类算法对战场信息进行分类,构建用席位兴趣模型,最后计算席位兴趣模型和候选信息之间的相似度并向席位推荐其感兴趣的战场信息。
参考文献
[1] 刘玮.电子商务系统中的信息推荐方法研究[J]. 情报科学, 2006, 24(2): 300-303.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



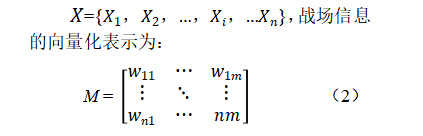 其中表示关键词在战场信息中的权重。
其中表示关键词在战场信息中的权重。