国家高速列车青岛技术创新中心
摘要:在多个行业中技术人员常会用到钢印与金属铭牌字符识别技术,钢印及金属铭牌字符主要刻打在各类硬质外表面上,多具有字符与背景颜色相近、背景易反光、字符印迹不明显、字符倾斜等特征。因此,使用传统方法对钢印及金属铭牌字符进行检测时,容易受到各类因素的干扰导致检测准确率低,此外传统方法的效果优化操作复杂且实现度较差。本文提出采用基于神经网络的金属序列号识别技术,有助于解决以上问题。
关键词:转向架;序列号;神经网络
引言:随着我国轨道交通的快速发展,城市交通拥堵的问题得到了很大的缓解,让我国城市的空间利用程度更加科学与合理。不过轨道交通为人们生活带来便利的同时,也面临了许多问题。动车组转向架组装完成后,在静压载荷试验期间时,零部件序列号由调试操作工手工填写至记录卡内,进行人工检验。由于填写方式的不科学,耗时耗力的同时,也导致各种填写错误频繁发生,无法满足零部件全寿命周期内的质量跟踪以及检修成本的降低。本文主要从基于神经网络的金属序列号识别技术来进行分析,有助于解决上述问题。
一、基于神经网络的识别技术
应用人工神经网络对转向架关键零部件金属序列号进行识别,主要包括以下环节:特征提取,人工神经网络的结构设计、网络训练与测试等。
1、特征提取环节
比较常用的特征提取方法主要包括像素特征提取法、骨架特征提取法、统计特征提取法以及13点特征提取法等。
2、网络设计环节
(1)网络结构的确定,网络结构的确定包括网络层数的确定和各层神经元个数的确定两部分。网络的输入和输出一定都是只有一层,现在只是隐层的个数需要确定。单纯从理论角度来看,网络隐层数越多,输出精度越高,但同时网络的结构也会越复杂,网络训练时间也会增加很多。大量的实践证明,只具有单隐层的典型三层网络结构能够解决很多实际应用问题,通过合理设置隐层神经元的个数可以使网络输出精度满足要求。这样既节省了训练时间,又简化了网络结构。BP 神经网络均为典型的三层结构,即一个输入层、一个隐层和一个输出层。
(2)激活函数和训练参数确定,每一层的激活函数都有几种可选,根据具体应用确定。选择输入层为S型双曲正切函数。采用了自适应动量法训练网络,初始权值和阈值采用随机生成。
3、网络训练环节
BP 神经网络的训练是一个简单重复的过程,但是对于网络的准确识别至关重要。
Step1:网络初始化,包括激活函数和各个训练参数;
Step2:根据一定的规则划分样本,对划分后的训练样本提取特征并输入网络;
Step3:根据样本特征进行信息的前向传播计算,并计算输出误差;
Step4:看输出误差是否满足训练要求,如果满足转至Step7;否则,转至Step5;
Step5:首先看是否已经到了最大训练步数,如果是,转至Step7;否则,进行误差的反向传播计算;
Step6:根据自适应动量学习规则,修正连接权值和阈值;
Step7:判断所有样本是否都完成训练,如果是,算法停止;否则,转至Step3。
当误差对连接权值的偏导数大于零时,权值调整量为负,实际输出大于期望输出,权值向减少方向调整,使得实际输出与期望输出的差减少;当误差对连接权值的偏导数小于零时,权值调整量为正,实际输出少于期望输出,权值向增大方向调整,使得实际输出与期望输出的差减少。
二、钢印与金属铭牌OCR识别技术
钢印及金属铭牌字符主要应用于各类硬质外表面上,如图1、图2所示。采用OCR方法对字符信息进行识别,详细步骤如下:


图 1钢印样例图 图2金属铭牌样例图
首先对原始图像进行预处理操作,得到初步清晰的图像,随后在检测阶段输入初步清晰的图像然后定位到文本框。共享阶段汇集backbone高层特征和检测器输出,然后使用校正模块对集合特征进行校正,并将其串联在一起形成一个字符相关特征。识别阶段,基于注意的解码器使用字符相关特征预测文本标签。
图像预处理(适用于钢印OCR及金属铭牌OCR)
传统图像处理(二值化、膨胀腐蚀等)
图像二值化就是将图像上的像素点的灰度
值设置为0或255,也就是将整个图像呈现出明显的黑白效果的过程。
Niblack 二值化
阈值的计算公式是:
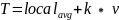 (1)
(1)
其中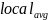 表示以该像素点为中心的区域的平均灰度值,
表示以该像素点为中心的区域的平均灰度值, 是该区域的标准差,
是该区域的标准差,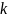 是一个可以调节的系数。
是一个可以调节的系数。
Sauvola二值化算法
阈值的计算公式是:
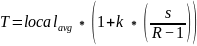 (2)
(2)
是可调节的阈值,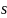 为局部像素和均值的标准差。
为局部像素和均值的标准差。
图像的膨胀(Dilation)和腐蚀(Erosion)是两种基本的形态学运算,主要用来寻找图像中的极大区域和极小区域。其中膨胀类似于“领域扩张”,将图像中的高亮区域或白色部分进行扩张,其运行结果图比原图的高亮区域更大;腐蚀类似于“领域被蚕食”,将图像中的高亮区域或白色部分进行缩减细化,其运行结果图比原图的高亮区域更小。
膨胀的运算符是“ ”,其定义如下:
”,其定义如下:
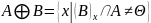 (3)
(3)
该公式表示用B来对图像A进行膨胀处理,其中B是一个卷积模板或卷积核,其形状可以为正方形或圆形,通过模板B与图像A进行卷积计算,扫描图像中的每一个像素点,用模板元素与二值图像元素做“与”运算,如果都为0,那么目标像素点为0,否则为1。从而计算B覆盖区域的像素点最大值,并用该值替换参考点的像素值实现膨胀。
腐蚀的运算符是“ ”,其定义如下:
”,其定义如下:
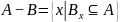 (4)
(4)
该公式表示图像A用卷积模板B来进行腐蚀处理,通过模板B与图像A进行卷积计算,得出B覆盖区域的像素点最小值,并用这个最小值来替代参考点的像素值。
超分辨率
传统的SISR只关心纹理的再恢复,忽略上下文信息,而文本图像具有很强的序列性。我们的最终目标是训练一个能够重建文本图像上下文信息的SR网络。首先,利用CNN进行特征提取。然后排列并调整特征地图的大小,因为水平文本行可以编码成序列。然后BLSTM可以传播误差差分,并将特征映射转化为特征序列,并将其反馈给卷积层。为了使倾斜文本图像的序列相关鲁棒性,从水平和垂直两个方向引入BLSTM。BLSTM以水平卷积和垂直卷积特征作为序列输入,在隐藏层中反复更新其内部状态。
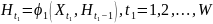 (5)
(5)
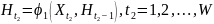 (6)
(6)
其中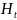 表示隐藏层,
表示隐藏层,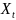 表示输入特征,
表示输入特征,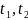 分别表示水平和垂直方向的循环连接。
分别表示水平和垂直方向的循环连接。
文字检测(适用于钢印OCR及金属铭牌OCR)
采用基于字符粒度的字符检测算法,输出是字符区域中心的概率和字符之间的关系。这个字符中心信息可以用来支持识别器中的attention模块,因为这两个模块都是为了定位字符的中心位置。
在相邻字符之间生成一个宽度为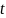 的线段,作为linkmap的GT, 的表达式如下:
的线段,作为linkmap的GT, 的表达式如下:
 (7)
(7)
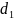 和
和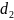 是相邻字符的对角线长度,
是相邻字符的对角线长度,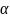 是尺度系数。 使用该公式可以使中心线的宽度与字符的大小成正比。
是尺度系数。 使用该公式可以使中心线的宽度与字符的大小成正比。
得到一个准确的文本框方向对于文本识别是至关重要的,于是,在检测阶段增加了2个通道的输出,这两个通道用来预测字符在水平和垂直方向的角度。生成GT部分,字符框向上的角度记为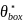 ,
,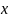 方向的GT记为
方向的GT记为
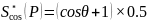 (8)
(8)
 方向的GT记为
方向的GT记为
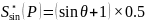 (9)
(9)
orientation map就是这两个方向上GT的结合。orientation map的损失函数定义如下:
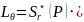 (10)
(10)
 和
和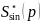 代表文本方向的GT,其中,字符区域得分
代表文本方向的GT,其中,字符区域得分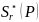 被用作加权因子,因为它表示字符中心度的置信度。方向损失只计算字符区域,即正样本。检测阶段最终的损失函数定义为:
被用作加权因子,因为它表示字符中心度的置信度。方向损失只计算字符区域,即正样本。检测阶段最终的损失函数定义为:
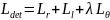 (11)
(11)
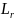 和
和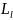 分别代表字符区域loss和链接loss,
分别代表字符区域loss和链接loss,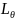 是角度loss,
是角度loss, 是控制权重。以下为未经图像预处理的检测结果:
是控制权重。以下为未经图像预处理的检测结果:

图 3文字检测识别结果
共享阶段
该阶段主要包含二大模块,文本纠正模块和字符区域注意力(text region attention, CRA)模块,使用薄板样条(TPS)变换去纠正任意形状的文本区域,文本纠正模块使用迭代-TPS,以获得更好的文本区域表示。
CRA模块是紧密耦合检测和识别模块的关键部件,通过简单地将校正后的字符评分图与特征表示连接起来,该模型建立了以下优点,创建检测器和识别器之间的链接允许识别损失通过检测阶段传播,这提高了字符评分图的质量;将字符区域映射附加到特征图有助于识别器更好地处理字符区域;
文字识别(适用于钢印OCR及金属铭牌OCR)
识别阶段有三个组成部分:特征提取、序列建模和预测。特征提取模块比单独的识别器更轻,因为它以高层语义特征作为输入。提取特征后,应用双向LSTM进行序列建模,并对基于注意力的解码器进行最终的文本预测。在每个时间步骤中,基于注意力的识别器通过屏蔽注意力输出到特征来解码文本信息。在识别阶段的损失函数定义为:
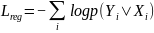 (12)
(12)
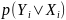 为第
为第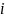 个单词框裁剪的特征表示
个单词框裁剪的特征表示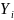 的字符序列的生成概率。
的字符序列的生成概率。
最终的损失函数为:
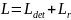 (13)
(13)
对检测结果进行识别
图 4待识别图片
钢印与金属铭牌OCR识别结果:
![]()
图 5文字识别结果
版面分析(针对金属铭牌OCR)
之前大部分版面分析算法是在检测网络上增加类别判断,预测位置的同时加上box类别的判断,但是这样通用性就大大降低了,违背不干预原始的OCR算法的初衷,版面分析的算法应该和OCR算法无缝衔接,所以模型输入应该是OCR输出的box坐标和相应文本。基于此,延伸出两个思路,一个是忽略box间的位置关系,直接将box坐标和文本编码,送入分类器,即基于xgboost的分类方案。另一个考虑box间的相互关系,将版面分析当成一种翻译任务,即基于seq2seq的翻译方案。
Xgboost的目标函数如下:
 (14)
(14)
其中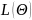 是误差函数,
是误差函数,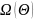 是正则化项。
是正则化项。
Seq2seq的Encoder公式为:
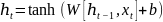 (15)
(15)
 (16)
(16)
其中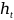 是隐藏状态,
是隐藏状态,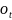 是输出。
是输出。
Decoder公式为:
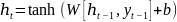 (15)
(15)
(16)
其中 。
。
结束语
轨道交通车辆转向架是轨道交通车辆当中最重要的系统之一,其安全性与人民的出行息息相关,零部件生产装配过程中的可跟踪、可追溯性关系到了后期维护保养以及行车安全,所以需要工作人员投入更多的时间与精力来对序列号管理问题进行研究,找到更加科学与合理的识别技术方案。
参考文献:
[1] 汪蕙, 鲍旭东, 罗立民. 车轮序列号自动识别系统[J]. 测控技术, 2002, 21(007):23-25.
[2] 胡琬聆, 张爽, 王雅红. 计算机视觉技术及其在工业中应用的研究[J]. 通讯世界, 2016, 000(002):239-240.
[3] 徐海波. 集成型车号自动识别检测系统[J]. 中外企业家, 2020, No.667(05):162-162.
[4] 段园园. 汽车轮毂型号自动识别系统[D]. 长春理工大学.
[5] 雷婷. 计算机视觉技术及其在工业中的应用探讨[J]. 科研:00150-00150.
[6] 黄遥. 基于OCR的视频字符识别技术研究与实现[D]. 北京交通大学, 2014.
[7] 金雪丹, 施朝健. 图像处理与神经网络识别技术在船舶分类中的应用[J]. 上海海事大学学报, 2007, 28(1):11-16.
[8] 徐勤涛, 杨自恒, 朱伟男,等. 基于神经网络的图像识别技术与方法探讨[J]. 通讯世界, 2018(7):100-101.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



