曲阜师范大学 山东省日照市 276800
音频信号作为生活中常见的蕴含特定信息的载体,已经成为人类获取信息以及传播信息最为有效的途径之一。为更好的确保公共场所下的安全需求,促进社会的和谐稳定,解决传统视频监控多盲区和滞后性等问题,本项目将深度学习引入到声学事件检测领域中,并基于卷积神经网络对声学事件自动检测技术展开研究。本项目计划先感知测量声信号,然后进行数字信号处理,在此基础上进行基于深度神经网络的自动特征提取与模式识别。最终实现基于深度学习的公共环境声学事件自动检测技术。
音频信号作为常见的一种承载了特定信息的载体,早已成为人类社会中获取信息以及传播信息的有效途径。随着人类步入信息社会,充分获取音频信号中的信息资源将对推动社会发展起到决定性的作用。近些年来,经济水平的显著提高,全球发展迅速,随之而来的就是安全问题,而传统的视频监控由于其耗费人力物力时间,多视觉盲区且具有滞后性,并不能满足当下对于安保的需要。随着音频事件检测技术的不断进步,音频监控有效弥补了视频监控的不足,它能辅助视频监控发挥出更稳定的监管性能,提高对特定的危险事件进行实时检测的成功率。同时声音通过介质振动进行传播,不容易受到障碍物的干扰,从而大大消除了监控盲区,采集音频信号流程简单快捷且存储需求较小,因此系统的算法复杂度较低,运行效率显著提高,并且维护和保障了公民的隐私权,满足于对空间私密性有特殊要求的场所。综上所述,音频监控能够使监控系统更加完善。本项目将深度学习与声学事件检测相结合,自动检测入侵事件,通过大数据的学习,提高音频信号识别精度。让计算机自动学习出模式特征,并将特征学习融入到建立模型中,从而减少人为设计特征造成的不完备性。
本项目主要采集爆炸声、玻璃破碎声、警报声和哭声等音频信号,通过连接在计算机上的麦克风实现音频信号的采集,并且将数据保存成WAV文件。为避免受到不恰当的声源信息的干扰,提高音频检测的准确性和效率,达到输出最优化,对收集的信号进行特征分析后使用改进的自适应滤波器对异常声音进行去噪,并基于自适应子带谱熵进行端点检测。本项目通过对前端处理的研究在一定程度上避免非目标声音以及各种环境噪声等不必要因素的干扰,提高了音频信号的整体质量,降低数据冗余和缩短运算周期。
为改善音频数据资源紧缺、解决音频样本数量相对有限的问题采用数据增强方法对音频事件的样本进行适当的扩充,其核心准则是保证音频数据的标签在转化变形前后的实际含义没有发生改变。在获得充足的声音样本的保障下,从音频信号中提取有效的特征参数对识别模型进行训练。声音识别算法是声学事件检测的核心和关键,通过对高斯混合模型识别算法和BP神经网络识别算法的研究,为基于卷积神经网络的声学事件识别算法性能提供比较的理论基础。
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络卷积神经络,可以视为标准神经网络的一种变形。通过卷积神经网络模型不同维度的研究,对一维声音信号特征将传统适用于二维特征的卷积神经网络的网络结构进行调整和改变,然后分析声音信号特征的维度对卷积神经网络识别性能的影响,对不同特征维度的卷积神经网络在噪声鲁棒性以及误差收敛速度等方面进行比较。通过和高斯混合模型、BP神经网络进行比较,分析、验证卷积神经网络在异常声音识别任务中的适用性及其识别性能。在音频信号的分析、处理和识别的基础上,用MATLAB平台开发基于卷积神经网络的声学事件自动检测系统,实现包括音频采集和输入、前端处理、模型训练和音频事件检测等四大部分。
基于深度学习的公共环境声学事件自动检测技术的研究技术路线如下图所示
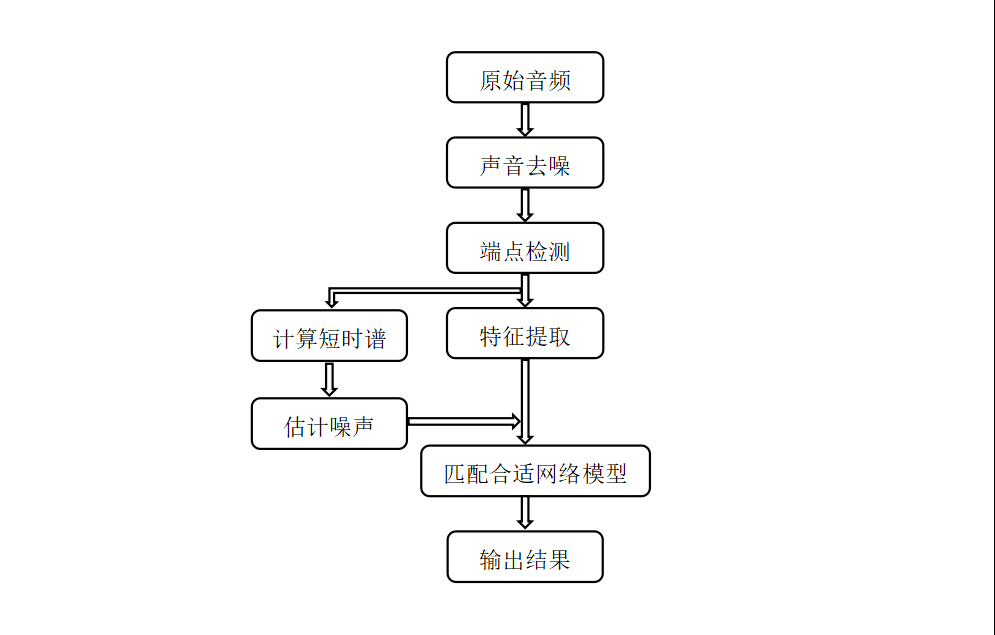
整体研究流程包括采集原始音频,对音频进行声音去噪,并基于自适应子带谱熵进行端点检测,通过特征提取进而匹配合适的网络模型。音频信号的前端数字处理和后端处理结束后,最终实现基于深度学习算法的异常声学事件识别。

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2025 期刊网(www.qikanchina.com) 琼ICP备2021005105号



