(重庆工程学院,重庆巴南,401320)
摘要:在深度学习技术的帮助下,手语识别的创新进展为聋哑人士提供了新的交流可能性。本研究基于ResNet101——一种深度卷积神经网络模型,通过迁移学习的策略,对模型进行了细致的调整和优化,使其更贴合手语的视觉特征。实验包括对部分网络层参数的冻结,输出层的重新设计,以及利用交叉熵损失函数和Adam优化器进行多轮次训练迭代。经过严格的实验验证,调整后的模型在手语图像数据集上表现出优异的准确率,显著提高了手语识别的实用性,进而为聋哑群体的社会融合和交流开辟了新的道路。
关键词:手语识别、深度卷积神经网络、ResNet101、迁移学习、视觉识别
1引言
1.1 应用背景
手语使用身体不同的部位,如手指、手臂、手部运动轨迹,头部和面部表情进行沟通的非言语交流方式[1]。对于聋哑人士而言,它不仅是日常交流的主要方式,也是一种文化和身份的体现。然而,非聋哑人士通常不会手语,这就造成了交流障碍,限制了聋哑人士在教育、就业和社会活动中的参与。手语识别作为一种特殊的交流方式,对于聋哑人士的日常交流至关重要。鉴于手语的复杂性和多样性,传统的图像处理技术难以达到高效和准确的识别效果。国内张淑军[2]等人已经对深度学习的图像识别技术进行了研究,但迁移学习的研究较少,不能看出迁移学习在图像识别领域的适用性。
随着人工智能的快速发展,深度学习在众多领域中的应用成为了研究的热点,尤其是卷积神经网络(CNN)在图像识别领域的成功应用[3],为手语识别提供了新的解决方案。其中,ResNet101模型因其深层次的网络结构和优秀的特征提取能力,被广泛应用于图像识别任务中。通过迁移学习,可以将这种预训练的深度模型应用于手语识别,从而克服传统方法的局限,提高识别的准确性和实时性。本文致力于探索ResNet101模型在手语识别中的应用,并探讨迁移模型在手语识别领域上的可行性。通过对模型进行调整和优化,使其适应手语图像的特点,从而提高了手语识别的准确率和实用性,对于改善聋哑人士的交流环境,促进其社会融合具有重要意义。
1.2 研究目的及思路
通过对聋哑人士交流障碍的关注和对深度学习技术在手语识别领域应用潜力的认识,虽然现有技术已经能够一定程度上识别手语,但依然存在准确率不高、实时性差、难以处理复杂背景下手势的问题。这些局限性使得手语识别技术在实际应用中受到限制,难以满足聋哑人士高效、流畅交流的需求。因此,探索一种更加高效和准确的手语识别方法成为了本研究的主要目的。在准确性方面主要利用深度学习技术,尤其是ResNet101模型的强大图像处理能力,提高手语识别的准确率,使其能够更准确地识别各种手势和动作。在应用过程中利用摄像头模拟复杂场景下手势识别的可靠性,通过改善手语识别技术在不同光照条件、背景复杂度等多变环境下的表现,使其在更广泛的应用场景中具有可靠性。
2.理论基础与相关技术
2.1卷积神经网络(CNN)原理
深度学习,作为机器学习的一个分支,近年来在人工智能领域取得了显著进展。它通过构建深层神经网络模拟人脑处理信息的方式,使得计算机能够从大量数据中学习复杂的模式和特征。深度学习的核心优势在于其能够自动并有效地提取数据的高级特征,这在图像识别、语音处理和自然语言处理等领域表现尤为突出。卷积神经网络(CNN)是深度学习中最成功的架构之一,如图1所示,特别适用于处理具有网格结构的数据,如图像(2D网格)和声音(1D网格)。CNN通过卷积层、池化层和全连接层的组合来自动提取和学习特征。

图1 CNN架构
卷积层:使用一系列可学习的滤波器(或称为卷积核)对输入数据进行卷积运算。这些滤波器能够捕捉局部特征,如边缘、颜色和纹理等。随着网络层次的加深,滤波器能够捕捉更加抽象和复杂的特征。
激活函数:如ReLU(Rectified Linear Unit)激活函数,用于引入非线性,使得网络能够学习更复杂的特征。
池化层:通常在连续的卷积层之后使用,用于减少数据的空间维度,降低计算复杂性,同时保留重要信息。最常见的池化操作是最大池化,即从输入的特征图中提取最大值。
全连接层:位于网络的末端,将前面层的输出转化为最终的输出,如分类标签。
2.2 CNN在图像处理中的应用
CNN在图像处理领域的应用表现非常出色,它能够有效处理图像的空间层次结构,从而在图像分类、目标检测和图像分割等任务中取得优异的性能。CNN通过学习图像中的局部特征,并逐层构建更复杂的全局特征,使其在处理图像数据时更为高效和精确。
在手语识别这样的特定任务中,CNN能够从手语图像中提取关键特征,如手部形状、位置和动作,为识别和理解手语提供强大的支持。通过深入训练和定制化的网络调整,CNN不仅能够提高识别准确率,还能够适应不同的环境和手势变化,从而在实际应用中展现出极大的灵活性和鲁棒性。
2.3 深度迁移学习概述及应用
深度迁移学习是一种有效的机器学习方法,它利用在一个任务上学到的知识,应用于另一个相关但不同的任务[5]。这种方法在数据集有限或者任务间存在某种关联时特别有用。深度迁移学习在手语识别中的应用,可以通过利用已有的大型图像数据集上预训练的深度神经网络,而本次实验使用的是Pytorch官网提供的预训练模型——Resnet101,来加速和优化手语识别任务的学习过程。
迁移学习的核心是利用预训练模型的特征提取能力。在手语识别的应用中,ResNet101模型因其深层次的网络结构和卓越的特征提取能力而被选用。该模型通过在大规模数据集上预训练,已经学会了丰富的视觉特征,这些特征可以通过微调过程适应新的手语识别任务。
在手语识别的具体应用中,深度迁移学习首先涉及将ResNet101模型的一部分层冻结,以保留模型在大型数据集上学到的通用特征。然后,调整模型的剩余层以适应手语识别的特定需求。这包括修改模型的输出层,以匹配手语识别任务的类别数,并通过在手语数据集上进一步训练模型来细化其权重。
深度迁移学习在手语识别中的应用带来了显著的优势。它不仅加速了模型的训练过程,还提高了识别的准确性,尤其是在数据有限的情况下。此外,利用迁移学习,即使是小型的手语数据集也能够训练出高性能的识别模型。
然而,迁移学习也面临一些挑战。模型的成功迁移依赖于源任务和目标任务之间的相关性。如果两个任务差异过大,直接迁移可能不会带来预期的效果。此外,过度依赖预训练模型也可能导致模型对特定手语数据集的过拟合。
2.4 ResNet模型概述
残差网络(ResNet)的基本原理是在传统深度神经网络的基础上引入了一种创新的结构——“残差学习”,以解决深度网络训练中的退化问题。当网络层数加深时,理论上网络应具有更强的学习能力,但实际上,过深的网络会导致性能下降,这主要是由于梯度消失或梯度爆炸问题造成的[4]。这样,即使网络层数加深,也能有效地传递梯度,从而避免梯度消失问题,提升网络的训练效果和性能。
在残差网络的设计中,每个残差块包含两个主要部分:一系列卷积层和一个跳跃连接。如图2所示,
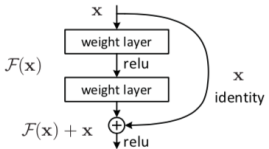
图2 残差网络的跳跃连接
跳跃连接实际上是一个恒等映射(identity mapping),它可以直接传递输入信息到块的末端,与卷积层的输出相加。这种设计使得网络在学习时,更加专注于学习输入和输出之间的残差,即微小的变化,而不是整个输出。因此,即使在深层网络中,也能保持较低的训练误差,并且提高了模型的泛化能力。残差网络因此在各种复杂的图像和视频处理任务中表现出卓越的性能,尤其是在高维数据处理和特征提取方面。
3.应用场景实验设计及过程
3.1 实验数据集介绍
本次实验数据集均来自人工搜集于互联网,其中训练集包含79512张图片,测试集包含24078张图片,总计103590,包括英文字母“A”至“Z”,图片实例如图3所示。

图3 不同的字母手语
3.2 实验优化过程
3.2.1 数据增强
在本次实验中为增加模型的健壮性以及提升模型在多变环境下的鲁棒性,同时为了减少模型的计算量,通过小幅度的裁剪将图片从中心开始裁剪至224*224大小,同时也为突出图像特征进行裁剪。随机将测试集中的图片进行水平翻转、垂直翻转、转换为灰度图,并通过调整测试集上的所有图片亮度、对比度、饱和度、色相等操作干扰模型的训练以增强模型的健壮性,提升了模型在多变环境下的鲁棒性。

图4 模型优化对比图
3.2.2 优化器选择
在本实验中,基于深度卷积神经网络ResNet101模型进行手语识别的应用探索,并采用了不同的优化器来提升模型的性能。具体而言,实验设计包括了Adam、RMSprop和SGD这三种不同的优化器,以观察它们对手语识别模型训练效果的影响
如图所示,Adam优化器在实验中展示了较高的准确性和较好的收敛速度。Adam优化器结合了RMSprop和SGD的优点,通过计算梯度的一阶矩估计和二阶矩估计来调整学习率,使其在许多情况下都能获得更好的结果。

图5 不同优化器模型性能
在实验的早期阶段,作者观察到RMSprop优化器在准确率提升上与Adam有着相似的表现,但随着迭代次数的增加,其性能增长开始放缓,最终准确率略低于Adam优化器。RMSprop通过对梯度的平方进行加权移动平均,调整每个参数的学习率,以防止学习率迅速降低到很小的值。
SGD(随机梯度下降)优化器作为一种基础的优化方法,在训练初期的收敛速度较慢,并且在整个训练过程中准确率的提升幅度相对较低。虽然SGD在调整权重时更为稳定,但缺乏动量参数,这在某些情况下可能导致收敛速度变慢。
从实验结果来看,不同优化器在模型训练中的效果有明显差异。Adam优化器由于其自适应性,对本次手语识别任务来说是最合适的,表现出了最佳的准确率和收敛性能。RMSprop次之,而SGD虽然稳健,但在面对复杂的手语识别任务时,其性能稍逊一筹。
最终,手语识别模型在测试集上达到了大约85%的高准确率,并显示出了优良的实用性和适用性。在实时交流场景中,模型经过优化后能够快速处理输入图像并给出识别结果,这对于聋哑人士的沟通提供了有效的技术支持。未来,将继续研究和改进模型,以进一步提升其在各种环境下的适应性和准确性
3.3 实验结果
在本文所述的“为残障人士打开新视界——基于ResNet101模型的手语识别创新应用”项目中,通过精确的实验结果来衡量模型的性能与实用性。本节详尽地展现了ResNet101手语识别模型在各阶段以及不同实验条件下的成效,涵盖准确度测试、性能对比,以及模型在现实世界应用场景中的实际效果和用户反馈。
经过三十轮训练迭代后,模型显示出正确率的显著提升,测试集上的准确率可达大约85%,如图6所示

图6 损失下降情况
并且本次实验的模型的损失能减少至0.6左右,而在测试集上的正确率如下图7所示,正确率能达到85%左右

图7 正确率情况
进一步的训练,涉及到更深层的3x3卷积层、最大池化层及全连接层,使得模型在训练集上的表现提升至85%,并在测试集上实现了最高89%的准确率,训练效果如下图8所示。

图8 正确率情况
3.5 模型性能的评估
本研究采用的ResNet101模型在手语识别任务中展现了显著的性能。通过使用初始学习率为0.001,并在每7次迭代后将其降低至原来的十分之一,模型成功地适应了手语图像的识别需求。利用Adam优化器,配合32张图像的批次大小,实现了高效的训练过程。
ResNet101模型在手语识别方面达到了约85%的高准确率, 模型的响应时间对于实时交流场景极为关键。本实验中的模型经优化后,能够快速处理输入图像并给出识别结果,大大提高了用户交流的流畅度,为聋哑人士提供了实时有效的交流支持。
通过在预处理阶段采用数据增强技术(如图像裁剪、水平翻转、亮度调整等),实现了模型对不同光照条件和复杂背景的强大适应性。该模型同样展现了对不同用户群体(包括不同年龄、性别、肤色等)的良好适应性,保证了模型的普适性和包容性。
ResNet101模型在手语识别任务中表现突出,但仍存在一些限制和改进空间。例如,模型对某些细微手势的识别准确率仍有提升空间,这可能与训练数据的多样性、质量或模型本身的架构有关。未来的工作将集中在扩大和多样化训练数据集、进一步优化模型结构、以及探索新的算法来提高模型的准确性和鲁棒性。
4.小结
本研究成功实现了ResNet101模型在手语识别准确率上的显著提升,尤其是在复杂手势和连续动作识别方面的表现,证明了迁移学习在此领域的有效性。模型保持高准确率的同时,实现快速响应,满足了实时交流的需求,为聋哑人士提供了有效的沟通工具。该项目显著改善了残障人士的交流能力,提高了他们的社会参与度和生活质量。
当前数据集在多样性方面存在不足,特别是对不同文化背景下手语的识别能力需进一步增强。同时也是本次实验的局限性,未从网络上搜集到有效质量高的中文手语数据,这也体现出当前中文手语数据集的缺失。
模型在极端光照条件和动态背景下的性能存在局限,需提高其环境适应能力。来工作将着重于扩大和多样化数据集,涵盖更多语言和文化背景下的手语数据。探索更高效的算法和网络架构,以进一步提升准确率和处理速度。
参考文献:
[1]米娜瓦尔·阿不拉,阿里甫·库尔班,解启娜,耿丽婷.手语识别方法与技术综述[J].计算机工程与应用,2021,(18)
[2]张淑军,张群,李辉.基于深度学习的手语识别综述[J].电子与信息学报,2020,第42卷(4): 1021-1032
[3]严春满,王铖.卷积神经网络模型发展及应用[J].计算机科学与探索,2021,15(1): 27-46
[4]郭玥秀,杨伟,刘琦,王玉.残差网络研究综述[J].计算机应用研究,2020,第37卷(5):1292-1297
[5]黄兆培,张峰源,赵金明,金琴.情感识别中的迁移学习问题综述[J].信号处理,2023,第39卷(4): 588-615
项目名称:2023年大学生创新创业训练项目s202312608011-“智音”vision

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



