中国电子科技集团公司第二十八研究所 南京 210007
摘 要:为了提高大型网络系统故障修复效率,智能故障解决方案推荐逐渐成为网络管理领域关注的焦点。网络管理系统收集了大量的故障现象、解决手段等数据,如何对故障数据进行有效分析和处理,并给出可能的故障解决方案供网络管理人员参考,辅助网络管理人员进行维护管理工作已经成为一个关键问题。本文从故障处理出发,通过构建维修特征推荐系统,根据用户维修事件相关描述信息,推送关联维修建议,从而满足大型网络数字化场景的运维需求。
关键词:网络管理;网络故障;解决方案推荐
1引言
大型网络系统的故障表现形式较为复杂,解决故障往往要依靠维护维修人员和专家现场排查,并根据自己的经验和知识进行故障处置,这种方式效率较低。与此同时,网络管理系统积累了大量的故障处理案例信息,其中包括故障现象(例如故障告警日志,性能告警日志)、故障类型、解决手段等数据,这些含有许多有用的故障解决方案知识,但这些知识以结构化、非结构化形式散落在系统中,这些数据存在多链性、多样性的特点,加之故障日志和解决手段存在人工口语化表达、对故障现象、原因定位、解决方案的描述没有统一的格式规定,也没有相应的解决方案分析提取机制,导致这些已有的故障解决方案信息没有进行有效的利用。
大型网络故障解决方案推荐就是将网络管理方面的专家知识和大量告警日志记录、说明书、维修手册、用户手册作为研究数据,当告警发生时,运用文本分析查找出与当前故障状态最匹配的故障处理建议方案,为工程师提供决策支持,基于这种模式可以提高工程师的故障处理效率,从而为减少告警量和提高告警处理效率提供决策分析[1]。
2总体架构设计
如何从大量故障维修知识文献中归纳总结故障文本数据的特征,本文研究对现有故障处理数据的组织和利用,对故障数据进行提取分析,并和专家知识及大量诊断报告、说明书、维修手册、用户手册等相关数据资源整合形成故障维修知识。通过语义分析工具,将维修知识分解为中文分词,并通过设备、故障及维修方案权重比较,保留关联性强的分词;通过 BERT-BiLSTM-Att 深度神经网络构建故障文本维修数据信息实体抽取模型,构建故障知识信息,将故障知识信息整合为故障库。
设备故障处置推荐方法流程如下图所示,当网络系统出现故障时,用户上传故障设备及故障特征信息,当用户选择“维修建议”后,通过语义分析预处理故障设备及故障特征文本信息,将上述信息按照词库匹配并结合领域词典完成分词。基于权重剔除无关分词,分别基于故障设备特征分词、故障描述分词进行实体识别,进行故障诊断,故障诊断分为对故障特征的向量化,对故障现象的分类查询和对查询结果的相似性匹配,向用户推送最优决策信息,并按照最终维修结果符合程度增减辅助决策信息权重。在工作人员完成故障处置后,将该次处置过程记录下来,经过知识抽取与储存等处理后,更新到故障库中,以便后续更好地完成故障处置推荐工作。
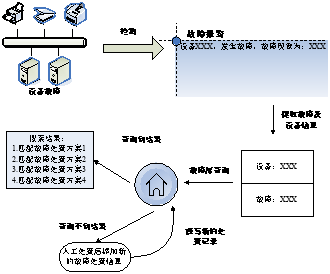
图1设备故障处置推荐方法流程
3告警数据预处理
大型网络故障数据获取来源主要分结构化数据和非结构化数据两类,结构化数据主要来源于网络管理系统的导出告警处置记录,可以从中提取告警设备名称、故障类型、描述、解决方案这几个关键字段;非结构化数据主要来源于专家知识和大量诊断报告、说明书、维修手册、用户手册等非结构化原始语料,这些数据基本信息量庞大,可能存在格式不标准、标点错误、乱码符号等问题,例如填写时误在反馈栏填写了故障描述,而且这些数据冗余信息过多,语义可能被切割导致不合理等情况,因此,在进行数据分析挖掘前,需要对原始的数据进行数据预处理,消除大量冗余数据,获得无噪声的文本信息[3]。数据的预处理过程包括:数据清洗、数据校验、领域词典构建、数据标注、文本分词、删除停用词,初步形成相对规范的标准化数据,数据预处理流程如下图所示。
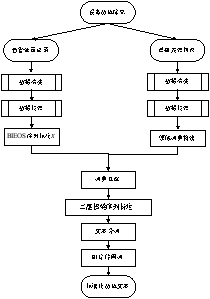
图2数据预处理流程
1)数据清洗
网络管理系统导出告警处置记录可能会存在某些数据字段丢失或异常等情况,因此数据预处理需要处理记录中的脏数据,将数据根据规则做清洗、过滤及转换处理,去掉不满足要求的数据,提升数据质量,对于问题数据,制定问题数据的处理策略,如表1所示。
表1 问题数据处理建议
数据类型 | 清洗策略 |
不完整数据 | 默认值填充策略 |
均值估计策略 | |
前后数据补全 | |
错误数据 | 文字标准化 |
时间标准化 | |
地点标准化 | |
坐标标准化 | |
预先定义的错误策略 | |
重复数据 | 按主键去重 |
按规则去重 | |
不一致 | 变化函数 |
格式化函数 | |
汇总分解函数 | |
预先定义规则 |
2)数据校验
告警处置记录经过数据清洗后可以基于组件库提供的数据值域范围、空值校验、数据校验、标点符号校验等组件,实现告警处置记录合法性识别与判断,不合法的脏数据则可以丢弃或者填充、转换等方式处理。如表2所示。
表 2 数据校验规则
类型 | 校验规则 |
值域校验 | |
字段值比对 | |
正则表达式校验 | |
空值校验 | |
数据格式校验 | |
精度校验 | |
数据范围校验 | |
记录数缺失校验 | |
重复数据校验 | |
不一致数据校验 | |
自定义规则 | 用户自定义规则 |
定制规则 | 包括数据校对规则、数据归一规则等 |
3)领域词典构建
本系统构建大型网络系统领域词典的流程如下图所示。为使所建立的词典能够尽可能满足后续数据分析和识别的需求,本文针对多数据源相关信息进行筛选清洗转换,数据源包括设备厂商提供的常用故障解决方案、说明书、维修手册、用户手册其中整理出来的基础信息、网络管理平台基础信息以及百度百科、中国知网等权威性网站中下载的相关领域知识数据信息等先验知识。将获取到的信息进行字段拆分合并、数据分类匹配等操作,得到不同类型的词汇信息,最终将不同词汇信息合并成领域词典。

图3 领域词典构建流程
4)词边界半自动标注
综合考虑业务特点和技术复杂度特性,为了在保证专业领域数据标注准确性的前提下减轻了网络管理相关业务人员标注的工作量,本文采用了一种基于领域词典的标注方法BIEOS,对于训练数据标明实体的开始位置(B)、中间位置(I)、结束位置(E),O表示该字符为一个单独的实体,N表示非实体,基于领域词典的词边界标注方法具体步骤如下:
步骤 1:对于故障文本序列集合𝑇 = 𝑇1…𝑇𝑛,首先从文本中抽取出故障部件实体(EQUIP)、故障描述实体(DESC)、维修部件实体(REPAIRE)、维修动作实体(SOLVE)四个实体的标注目标进行自动+人工辅助核验双重标注,得到序列标注𝑋。
步骤 2:利用前面建立的领域词典𝐷,与故障文本序列𝑇词典匹配,得到匹配结果𝑌 = ![]() 。
。
步骤 3:利用极大似然估计计算故障文本序列𝑇的联合条件概率,如式(4-1)所示,最终得到二层核验序列标注𝑅。
![]()
5)文本分词
目前,针对中文文本的分词工具较多,本文选取了LTP工具对文本进行分词处理,同时由于LTP 4.1.0版本以上支持自定义分词,本文将前面建立的领域词典添加到LTP中,提高分词的准确性。
6)删除停用词
故障数据中例如“的”,“在”等停用词并无实际意义,通过读取预先设定的中文停用词表,利用该词表去除文本中无实际意义的词语,并将数据集加入语料库。
4故障知识提取
在进行故障解决方案相似度匹配时,预处理后的自然语言文本无法被计算机识别与运算,需要将待处理文本向量化,在故障知识提取部分,主要通过对原始的输入语料进行处理,查找相应的词向量表和字向量表获得语料中每个词的词向量表示和字向量表示,并组建字向量矩阵,采用加权融合方式对字向量矩阵进行处理,将处理过的字向量与原来的词向量进行拼接得到最终的输入向量,然后通过注意力机制和BLSM递归神经网络模型联合对重要故障知识进行重点识别,最后通过Jaccard相关系数、Consine距离来计算相似度完成故障知识融合[3]。
1)词向量提取
词向量是一类需要大量包含词的上下文信息的数据进行训练的语言模型,本文利用Word2Vec获取数据空间故障相关文本的词向量表示。目前中文领域常见的公开训练词向量模型一般使用维基百科、人民日报等较大规模的公开通用语料库。但是由于采集得到的故障相关文本内容具有一定的随意性,用语习惯与通用语料库中的语料不尽相同,为了获得更适合本文工作的词向量,本系统不选择公开的预训练模型,而是使用采集到的大量故障相关数据作为基底语料,采用基于Skip_Gram模型结构的 Word2Vec 对分词后的文本数据进行词向量的预处理,获得词汇特征。
2)字符特征获取
本文所研究的故障相关文本数据如某一条通信控制器设备故障解决方案描述为“通信控制器设备开机电源灯不亮,经检查发现是电源模块没有输入或输出,更换保险丝。”中,出现“发现”字段的多为故障原因,出现“更换”字段的多为解决方案,这类文本数据具有强有力的上下文特征,由于 Word2Vec 只对每个字符有一个固定表示,与该字符出现的上下文无关,而字特征向量能够有效地反映出中文汉字的意义,尽可能的表达文本的语境。为弥补Word2Vec词向量表示的不足,本文利用具有较强语义表征优势的BERT模型对文本数据的字符特征进行训练, BERT 模型训练[4]所需的语料库巨大且训练耗时,因此本文直接采用谷歌提供的中文版 BERT 模型对故障文本计算单个字符的向量表示。
3)字词向量融合
为提高故障相关文本数据实体识别的准确率,本文采用加权融合方式将词向量特征匹配到对应字符特征中[5],即为每个字符选择一个最可能的词汇信息,将处理过的字向量与原来的词向量进行拼接得到最终的输入向量。具体步骤如下:
步骤1:将字符C与所有相关的分词进行匹配,得到该字可能出现的所有实体标记,由于本文采用基于领域词典的BIEOS标注方法,所以一个字符C的C (![]() )由B(
)由B(![]() )、I(
)、I(![]() )、E(
)、E(![]() )、O(
)、O(![]() )、S (
)、S (![]() )组成,其中开始位置B(
)组成,其中开始位置B(![]() )表示所有以字符C开始的实体、
)表示所有以字符C开始的实体、![]() 表示在领域词典中包含该字符的词汇实体类别。
表示在领域词典中包含该字符的词汇实体类别。
![]()
步骤2:获得字符C对应的B(![]() )、I(
)、I(![]() )、E(
)、E(![]() )、O(
)、O(![]() )、S (
)、S (![]() )后,利用加权平均的方式将这五个词汇标注集合组成词汇向量W(
)后,利用加权平均的方式将这五个词汇标注集合组成词汇向量W(![]() ),其中K(
),其中K(![]() )就是指字符C对应的B(
)就是指字符C对应的B(![]() )、I(
)、I(![]() )、E(
)、E(
![]() )、O(
)、O(![]() )、S (
)、S (![]() ),
),![]() 是匹配得到的词汇出现的词频。
是匹配得到的词汇出现的词频。
![]()
步骤3:将词汇向量W(![]() )添加到BERT提取的字符特征C (
)添加到BERT提取的字符特征C (![]() )中,拼接得到最终特征 X(
)中,拼接得到最终特征 X(![]() ):
): ![]()
![]()
4)BLSM递归神经网络模型
双向LSTM递归神经网络模型,即BLSM(Bipolar Long and Short-Term Memory)递归神经网络模型。双向的LSTM递归神经网络就是将句子采取不同的方向进行递归,即顺序和逆序,通过使用双向LSTM递归神经网络,语句中的每个词语都能得到完整的上下文信息。本文使用双向LSTM递归神经网络处理故障领域文本的输入向量,并得到相应的特征向量。具体如下图所示。其中![]() 表示T时刻双向递归神经网络的输入向量,
表示T时刻双向递归神经网络的输入向量,![]() 表示双向递归神经网络的输出向量。
表示双向递归神经网络的输出向量。

图4 BLSTM结构
5)基于特征实体注意力形成故障特征
自注意力可以提取句子本身的词间依赖,把注意力机制和BLSM递归神经网络模型联合,目的是为充分表达与故障相关的重点信息,能够将故障数据中的重要维修知识进行重点识别,减少其他不重要词汇的影响,本文通过注意力机制赋予BLSM输出特征向量的相应权值,从而得到最终的输出向量。具体步骤如下,其中,![]() 是计算节点i较节点k的自注意力权重、C为编码语义。
是计算节点i较节点k的自注意力权重、C为编码语义。![]() 是最终生成的特征矢量:
是最终生成的特征矢量:
![]()

![]()
6)故障知识融合
故障知识融合是将从不同文本中抽取的多源信息进行合并,本文通过Jaccard相关系数、Consine距离来计算实体和属性相似度以确认抽取文本是否为库中相同的实体,最终将其链接到故障知识库中相对应的实体对象上。
5方案匹配结果推荐
故障解决方案匹配是根据故障设备自身情况以及出现的故障现象给出故障原因和解决方案推荐,故障知识的匹配步骤即网络管理人员上传的故障设备和故障现象和能提供的故障知识及故障设备相匹配的语义相似度及设备相似度问题,方案匹配结果推荐会预先对于用户上传故障设备及故障特征信息,再一次经过分词、去停用词等预处理处理方法抽取其中关键词或短语,然后基于设备相似度和故障相似度最近原则进行方案匹配结果的提取[5],通过排序算法对其进行排序,输出相似度最高且无冗余信息的解决方案文本,得到一个准确的方案匹配结果,具体步骤如下图所示。

图5方案匹配结果推荐流程
1)故障语义相似度匹配
对于网络管理人员输入的故障现象信息,经过预处理、分词、标注、删除停用词等过程后,可以设故障现象实体序列为![]() ,故障知识数据的实体序列为
,故障知识数据的实体序列为![]() ,从而得到X 和 Y 间的语义相似度矩阵
,从而得到X 和 Y 间的语义相似度矩阵![]() ,其中
,其中![]() 每行元素代表故障现象实体序列
每行元素代表故障现象实体序列![]() 里某一实体和所提供故障知识数据序列
里某一实体和所提供故障知识数据序列![]() 里所有的实体都计算相似度。
里所有的实体都计算相似度。
![]()
对![]() 每行实体所得相似度并取最大值后求其平均值,能够得到 X、Y,获得对该故障解决方案的候选故障解决方案集,然后基于故障语义相似性分析利用根据两矢量间的余弦距离大小对候选集进行过滤,相似性的计算公式如下,其中
每行实体所得相似度并取最大值后求其平均值,能够得到 X、Y,获得对该故障解决方案的候选故障解决方案集,然后基于故障语义相似性分析利用根据两矢量间的余弦距离大小对候选集进行过滤,相似性的计算公式如下,其中![]() [6]表示故障知识数据
[6]表示故障知识数据![]() 对于故障知识搜索建模的R的语义相似度,
对于故障知识搜索建模的R的语义相似度,![]() 表示故障知识
表示故障知识![]() 中某一实体
中某一实体![]() 所占的比例,
所占的比例,![]() 表示网络管理人员搜索故障知识R中对应实体
表示网络管理人员搜索故障知识R中对应实体![]() 所占的比例。
所占的比例。

2)设备相似度匹配
本研究告警数据预处理章节中领域词典构建模块基于设备故障处置相关文档抽取其中设备名词类术语并根据设备之间关系构建网络设备词典,词典为多层树状结构,如果两个设备之间距离越近,则设备相似度越近。将设备相似度与上一节得到的语义相似度结合得到故障相似度,最后选取故障相似度最近的故障的处置方案为最终推荐方案。
首先从故障记录文本 X 中提取故障类型 C、故障设备 D 和故障描述信息Z,然后从故障知识库中筛选所有故障类型为![]() 的故障案例信息
的故障案例信息![]() 作为备选案例,其中 R 表示故障处置方案,n为备选案例总数。通过前文计算故障描述信息 Z 与候选故障案例中各描述信息
作为备选案例,其中 R 表示故障处置方案,n为备选案例总数。通过前文计算故障描述信息 Z 与候选故障案例中各描述信息![]() 的文本相似度
的文本相似度![]() ,然后借助领域词典计算故障设备 D 与
,然后借助领域词典计算故障设备 D 与![]() 的相关程度
的相关程度![]() ,将故障描述信息相似度与设备相关度求和得到最终的故障相似度
,将故障描述信息相似度与设备相关度求和得到最终的故障相似度![]() ,取故障相似度最大值
,取故障相似度最大值 ![]() ,说明故障案例信息中第i个故障与当前故障最相似,则其对应的故障处置方案
,说明故障案例信息中第i个故障与当前故障最相似,则其对应的故障处置方案![]() 为最终推荐处置方案。
为最终推荐处置方案。
6结束语
本文以大型网络故障处理领域为研究对象,基于故障设备及故障故障特征信息构建特征向量,对现有数据空间的故障数据进行提取分析,并和专家知识和大量诊断报告、说明书、维修手册、用户手册等相关数据资源整合进行文本知识转换,构建支持迭代更新的故障维修知识库,以 BERT-BiLSTM-Att 深度神经网络为基础建立“设备故障信息-维修方案”故障文本知识抽取模型。将对应设备历史故障信息建立候选集合,候选集合经过故障设备相似度和语义相似度匹配推荐生成最优结果,最终推送至用户形成推荐策略。实现了故障维修数据的知识化和知识的服务化,有助于提高维修效率及维修质量,提升维修的精准化及规范化。
参考文献
[1] 郭喜跃, 何婷婷. 信息抽取研究综述[J]. 计算机科学, 2015, 42(2):14-17
[2] Graves A, Schmidhuber J. Framewise phoneme classification with bidirectional LSTM and
other neural network architectures[J]. Neural networks, 2005, 18(5-6): 602-610..
[3] 张莉.基于词向量扩展的语义检索模型研究[D].成都:电子科技大学,2020.
[4] DEVLIN J,CHANG M W,LEE K,et al. BERT:pretraining of deep bidirectional transformers for language understanding[EB/OL].(2019-05-24)[2021-09-10]. https://arxiv.org/pdf/1810.04805.pdf.
[5] GAO W,ZHENG X,ZHAO S.Named entity recognition method of Chinese EMR based on BERT-BiLSTM-CRF[J]. Journal of Physics:Conference Series,2021,1848(1):012083..
[6] 刘剑,许洪波,唐慧丰等.面向中文网络百科的语义知识库构建[J].系统仿真学报,2016,28(3):542-548.
温馨(1991-)女,工程师,研究方向为网络管理技术。

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



