中车石家庄车辆有限公司
摘要:生产安全是工厂的重中之重,划分出危险区域并进行安全驱离具有重要的意义,因此提出了一种基于改进的YOLOv5特定区域图像识别技术,通过对采集的实时视频进行处理、对YOLO模型中图像进行特定区域的划分,可以实现在移动端,或者性能较低的设备上进行图像实时监测和危险区域的划分。
关键字:区域识别;YOLO;实时监控
Abstract:Production safety is the top priority of the factory. It is of great significance to pide dangerous areas and drive them away safely. Therefore, an improved YOLOv5-based image recognition technology for specific areas is proposed. By processing the collected real-time video and piding the images in YOLO model into specific areas, real-time image monitoring and dangerous area pision can be realized on the mobile terminal or low-performance equipment.
Keywords: area identification; YOLO; real-time monitoring
0引言
安全生产是工厂的重中之重,必须要坚守“人民关天,发展决不能以牺牲人的生命为代价”的安全生产红线意识,研究发现安全生产事故绝大部分都是由于工作人员违规违章造成的。为了一时的便利或者意识的疏忽而进入工厂危险作业区域造成严重后果的案例历历在目。因此研究一套可以通过工厂监控设备,划定特定的危险区域,当有违规人员进入时,进行警告驱离就具有了现实的研究价值。
近些年,人工智能技术快速发展和应用,在目标检测领域,一批高精度的算法不断刷新了识别精度的上限,并在工业界广泛使用。2015年,Redmon J提出了YOLO检测算法,该算法速度能达到每秒45帧。
YOLOV1存在召回率低和定位不准的缺点。经过Joseph Redmon等人的改进,YOLOV2和YOLO9000算法在2017年CVPR上被提出,并获得最佳论文提名,重点解决了召回率和定位精度方面的问题,其采用Darknet-19作为特征提取网络,增加了批量归一化(Batch Normalization)预处理,并使用224×224和448×448两阶段训练。YOLOV2借鉴了Faster R-CNN的思想,引入Anchor机制,利用K-Means聚类的方式在训练集中计算Anchor模板,在卷积层使用Anchor Boxes操作,增加候选框的预测,同时采用较强约束的定位方法,大大提高算法召回率。
YOLOV3主要在网络结构上的进行了改变,特别是将主干网络改成了Darknet-53。相较于YOLOV3的DarkNet53,YOLOV4使用了CSPDarkNet53,并在YOLOV3的基础上增加了PAN。此外,YOLOV4使用了CutMix数据增强、Mosaic数据增强和DropBlock正则化。
YOLOV5在数据增强方面采用了缩放、色彩空间调整与Mosaic数据增强。相较于YOLOv4,YOLOv5有自适应锚点框,其锚点框是基于训练数据集自动学习的。YOLOV5采用的激活函数包括leakyReLU和Sigmoid。
由于移动端及工厂的工控机等设备性能较弱,无法像实验室中采用高性能计算机和GPU对视频图像进行训练和测试。因此,本文的重点集中在如何在性能相对较低的设备上实现视频图像的实时监测。本文采用YOLOv5s轻量级模型进行设计,改进模型中对视频处理的方式,在不影响检测精度的情况下,与未改进的YOLOv5s算法进行对比与分析。
1目标识别算法
1.1目标识别算法介绍
Yolov5s是yolov5系列中深度最小,特征图宽度最小的网络,yolov5网络结构主要包括输入端、支柱层(backbone)、特征融合层(neck)、输出端四部分[引用]。YOLOv5与YOLOv4在结构上基本相似,只是在细节上稍有差异。
1)输入端
Yolov5的输入端采用了和Yolov4一样的Mosaic数据增强的方式。提升了对于小目标的检测效果。相较于YOLOv4,YOLOv5有自适应锚点框,网络在初始锚框的基础上输出预测框,进而和真实框进行比对,计算两者差距,再反向更新,迭代网络参数。
2)支柱层(backbone)
yolov5的支柱层采用Focus结构和CSP结构,Focus结构的核心是对图片进行切片操作。原始608×608×3的图像输入Focus结构,采用切片操作,先变成304×304×12的特征图,再经过一次32个卷积核的卷积操作,最终变成304×304×32的特征图。
Yolov5中设计了两种CSP结构,以Yolov5s网络为例,以CSP1_X结构应用于支柱层(Backbone),另一种CSP2_X结构则应用于特征融合层(Neck)中。
3)特征融合层(Neck)
yolov5采用FPN+PAN的结构, FPN层自顶向下传达强语义特征,而PAN是底层金字塔,自底向上传达强定位特征。
4)输出端
Yolov5采用加权的nms非极大值抑制。采用CIoU_Loss做Bounding box的损失函数。公式为:

其中,v是B与G长宽比的距离:

α是一个权重系数:
![]()
1.2目标识别算法的改进
1)视频输入端的改进
Yolov5模型使用opencv程序调取视频流,但是VideoCpature中的read函数是按帧读取,图像文件形成一个先进先出的队列。在较低性能的设备上模型处理图像的能力是有限的,容易造成传入帧数与处理帧数不对等的现象,待处理图像积压严重,视频处理延迟很高,无法实现实时监控。鉴于此项问题,项目组通过研究讨论,决定对rtsp视频流传入yolov5s模型前进行处理,改进yolov5模型中视频调用的函数。项目组提出的方案是,改造视频读入函数VideoCapture,设计一个共享栈,利用多进程方式,将读取视频和处理视频分离为两个进程,分别向共享栈中写入数据和读出数据,当共享栈满时即自动清空栈,保证处理视频进程每次读取的都是最新的视频帧。保证yolov5s模型每次处理的图像都是最新的,以满足实时监控的需求。
2)实现图像区域识别
Yolov5s识别传入图片的所有区域,无法达到仅识别特定区域的效果。本项目采用的是固定监控摄像头,需要检测的区域相对固定。因此,对传入的图像进行大小调整和填充之后,划分出“感兴趣区域”覆盖原始图像,仅暴露“感兴趣区域(IoU)”,这种模板图像叫做掩模。将处理以后的图像传入模型,yolov5模型仅对掩膜部分进行检测。
3)NMS非极大抑制改进
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要进行nms非极大抑制操作,yolov5使用了pytorch官方提供的NMS实现非极大抑制,此方案对有遮挡或者两个物体过于接近时,很有可能会将一个物体的预测框滤除。因此,需要将原模型中的NMS修改为DIoU_NMS,在传统NMS中,IoU指标常用于抑制冗余检测框,其中重叠区域是唯一因素,对于遮挡情况常产生错误抑制。DIoU_NMS将DIoU作为NMS的准则,因为在抑制准则中不仅要考虑重叠区域,而且还应该考虑两个检测框之间的中心点距离,DIoU正是同时考虑了重叠区域和两个预测框的中心距离,因此可以将DIoU_NMS中的si公式定义为:

其中同时考虑IoU和两个检测框的中间点距离来删除box B_i,s_i是分类得分,ε是NMS阈值。DIoU-NMS建议两个中心点较远的box可能位于不同的对象上,不应将其删除,利用此方案可以对一些遮挡重叠的目标实现更好的预测。
4)根据分类设计语音驱离。
在yolov5模型对输入图像特定区域预测完毕后,根据预测框的标签,如果是指定的“person”或“hat”类型,且目标的置信度大于等于设定值,即调用python中的语音包,对进入划定区域的人员进行语音驱离,如果超过设定时间未离开,即保存该时段图像信息,留存安全风险证据,以便对员工进行安全风险教育及考核。
2试验结果及分析
2.1 数据集训练与评估
数据集主要包括工厂现场工作人员数据和人员戴安全帽数据,采集现场3200张图片,使用LabelImg进行标注,生成xml文件,文件名和图片保持一致。并结合公开数据集VOC2028中的7581张图片,共10781照片。分为“person”和“hat”两个类别。模型训练的样本数据为数据集的81%,验证集为9%,测试集为10%。
训练集和验证集用于模型的训练和训练过程的验证,测试集数据用于MAP指标的计算。训练模型,使用yolov5s预训练权重,总共训练100个epochs,前50个epochs冻结主干参数,特征提取网络不发生变化,解冻阶段的学习率为1e-3,后50个epochs解冻主干参数进行训练,学习率为1e-4。训练的loss变化如图:
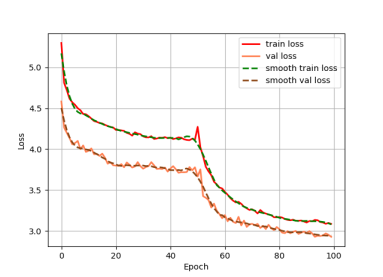
图一 训练loss
模型的好坏并不是迭代的次数越多越好,过多的训练容易导致模型过拟合,所以需要对训练出来的模型进行测试和评估。本文采用准确率(precision)、召回率(recall)、mAP来评估训练的模型。计算公式为:
![]()
![]()
![]()
式中TP为预测正确的正样本,FP为预测不正确的正样本,FN为预测的负样本,c为类别的数量, N 为引用阈值的数量, k 为阈值, P(k)为准确率, R(k)为召回率。模型的评估参数示意图如下:

图二 准确率(precision)

图三 召回率(recall)
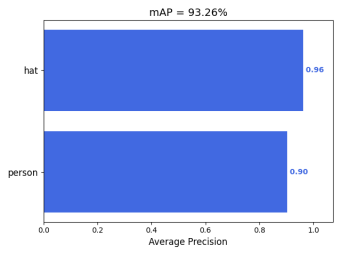
图四 mAP
2.2目标检测对比
本文使用的是嵌入式微型工控机作为试验平台,以实现目标检测系统的小型化,可移动化。使用网络摄像头采集实时图像。与未改进的yolov5s模型进行对比,经对比,未改进的yolov5s模型在实时检测中,存在10s左右延迟情况,并且因为视频流的堆积,容易导致内存溢出,程序崩溃。经改进后的yolov5s模型在实时监测中,有1.5s的延迟,并且可以在栈满后自动清空栈,保证所检测的图像是最新的,在需要进行实时驱离的场景中,有6.7倍的提升。通过改进视频传入方式,保证模型每次获得的图像都是最新的。

图五 现场测试效果图
3结束语
通过改进yolov5模型的输入视频方式、使用掩膜处理图像、改进DIoU_nms提高识别能力,试验证明对模型的改进是有效的,保证了性能较弱的设备可以对目标进行实时监控,可以实现对危险区域的监控警告。下一步的工作是进一步优化检测模型,提高模型的预测准确率。增加多场景的数据训练集,提高模型的泛化能力,增强系统模型的鲁棒性。使模型能够适应更加复杂的场景。

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



